

摘要:本指南介绍了网站爬虫下载的技术解析及合法使用。概述了爬虫的基本原理和目的。详细解析了下载网站爬虫的过程和方法,包括选择合适的爬虫工具、设置参数等。强调了合法使用的重要性,提醒用户遵守相关法律法规和网站使用协议,确保爬虫技术的合法、合规应用。
本文目录导读:
随着互联网的发展,网站爬虫下载技术日益受到关注,本文将介绍网站爬虫下载的基本原理、技术解析以及合法使用指南,帮助读者更好地了解这一技术,并能在实际工作中合理运用。
网站爬虫下载是一种自动化获取互联网资源的技术手段,广泛应用于数据挖掘、搜索引擎、内容聚合等领域,通过爬虫程序,我们可以从网站上抓取所需的数据、图片等信息,实现资源的下载和存储,在使用网站爬虫下载技术时,我们必须注意合法性和道德伦理问题,避免侵犯他人的权益。
网站爬虫下载的基本原理
网站爬虫下载的基本原理是通过模拟浏览器行为,向目标网站发送请求,获取网页的HTML代码,然后解析代码以提取所需的数据,这个过程涉及到以下几个关键步骤:
1、确定目标网站:明确需要爬取的网站和数据。
2、发送请求:通过爬虫程序向目标网站发送请求。
3、获取网页数据:接收目标网站的响应,获取网页的HTML代码。
4、解析网页:使用爬虫程序解析HTML代码,提取所需的数据。
5、数据存储:将提取的数据进行存储,以便后续处理。
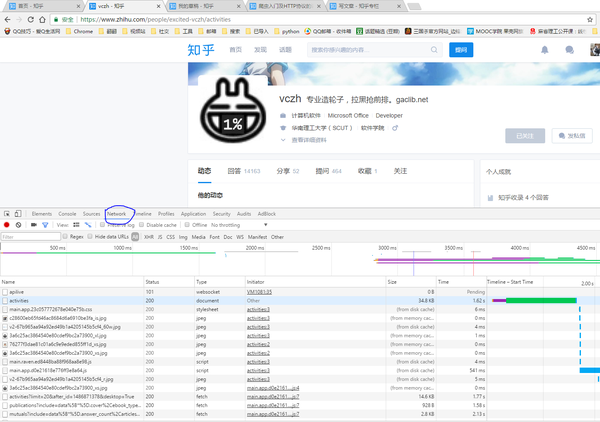
技术解析
网站爬虫下载技术涉及到多个领域的知识,包括编程、网络、数据结构和算法等,以下是关键技术的解析:
1、编程语言:网站爬虫下载通常使用Python、Java、C#等编程语言实现,这些语言具有丰富的库和框架,可以方便地实现网络请求、HTML解析等功能。
2、网络请求:使用HTTP或HTTPS协议向目标网站发送请求,获取网页数据。
3、HTML解析:解析HTML代码以提取数据,常用的解析库包括BeautifulSoup、Scrapy等。
4、数据存储:将提取的数据进行存储,可以选择将数据保存到数据库、文本文件或Excel表格等。
合法使用指南
在使用网站爬虫下载技术时,我们必须遵守法律法规和道德伦理,尊重他人的权益,以下是一些合法使用的建议:

1、遵守法律法规:了解并遵守相关法律法规,如《著作权法》、《计算机信息网络国际联网管理暂行规定》等。
2、尊重网站规定:在爬取网站数据时,尊重网站的使用协议和规定,避免违反使用条款。
3、合理请求频率:避免过于频繁地发送请求,以免对目标网站造成负担。
4、数据处理合规:对于爬取到的数据,要遵守隐私保护和数据安全的规定,不得滥用或泄露。
5、避免侵犯权益:避免爬取涉及他人隐私、版权等权益的内容,确保数据的合法性。
案例分析
为了更好地理解网站爬虫下载的合法使用,我们来看一个案例:假设某研究团队需要收集某个领域的学术论文数据,他们可以通过爬虫程序从学术网站爬取相关论文的标题、摘要等信息,在这个过程中,他们需要遵守以下规定:
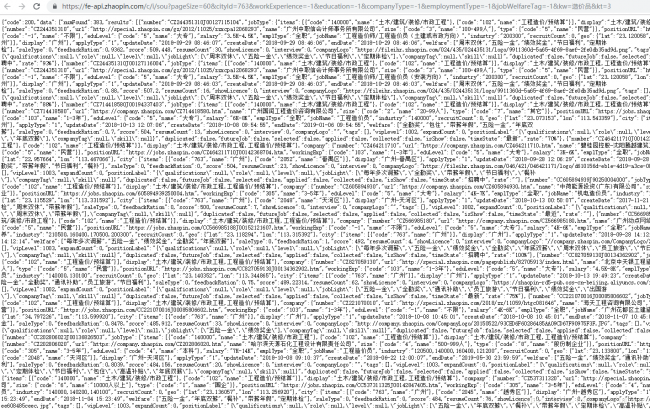
1、遵守《著作权法》的规定,确保爬取的内容不侵犯他人的版权。
2、尊重学术网站的使用协议,按照协议规定合理使用数据。
3、控制请求频率,避免对学术网站造成负担。
4、对爬取到的数据进行合规处理,确保数据安全。
网站爬虫下载技术是一项重要的互联网技术手段,但在使用过程中需要注意合法性和道德伦理问题,本文介绍了网站爬虫下载的基本原理、技术解析以及合法使用指南,希望读者能够更好地了解这一技术,并在实际工作中合理运用。
 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...